
예시) 영화 추천 시스템에 대한 이해
추천에 이용되는 협업 필터링(Collaborative Filtering) 주요 알고리즘 이해
- K-nearest neighbor (KNN) 알고리즘
- Matrix factorization 알고리즘
- Matrix factorization + PLSI 알고리즘
빅 데이터마이닝에서 많이 쓰이는 기술인 Probabilistic Modeling 기술을 습득
영화 평점과 영화에 대한 다른 텍스트 정보도 이용하는 알고리즘 구현
Python을 사용하여 빅 데이터 처리에 효율적인 코딩 실습
- Sparse matrix(희소 행렬) 형태의 데이터를 array에 zero 값들까지 그대로 저장하면 메모리도 많이 필요하고 수행 시간도 오래 걸림
- Python의 numpy 라이브러리의 행렬 연산과 scipy 라이브러리의 sparse matrix format을 사용하면서 reshape과 broadcasting 기법을 이용하여 효율적으로 코딩
======> 여기까지 빅데이터 추천에 대한 기본적인 설명이였는데 뭔말인지 하나도 모르겠으니 하나씩 알아보자
추천 시스템(Recommendation System)
말 그대로 어떠한 컨텐츠를 추천해주는 시스템인데 이게 왜 중요할까?
추천 시스템이 잘 만들어지면 친사용자 서비스이며 동시에 친기업 서비스가 될 수 있는 강력한 시스템
추천 시스템은 사용자의 취향을 파악한다
취향을 파악한다는 뜻은 컨텐츠를 분류하고 추천할만한 명확한 식별자(구분자)가 있다는 뜻이고 그것을 어떠한 알고리즘을 이용하여 선별하는 의미이다
여기서 이용하는 알고리즘은 여러가지가 있지만 대표적으로 콘텐츠 기반 필터링(Content based filtering), 협업 필터링(Collaborative filtering) 방식을 보려고한다. 더 나아가서는 딥러닝이나 하이브리드 방식도 있지만 너무 Deep하게는 알아보지 않기로 했다.
초반에는 콘텐츠 기반 필터링(Content based filtering)을 많이 사용했지만 넷플릭스(Netfilx) 같은 서비스가 나온 이후 협업 필터링(Collaborative filtering)을 사용한다고 한다. 이를 사용하기 위해 나온 개념이 행렬 분석(Matrix Factorization) 이다.
콘텐츠 기반 필터링(Content based filtering)
사용자가 특정 아이템을 선호하는 경우 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천해주는 방식
A라는 영화가 액션영화이면 액션영화를 추천해주는 시스템
다른 사용자의 아이템 소비 이력을 활용하는 협업 필터링(Collaborative filtering) 과는 주로 사용하는 데이터가 다르다
아이템이 유사한지 확인하려면 아이템의 비슷한 정도(유사도, similarity)를 수치로 계산할 수 있어야함
유사도 계산을 위해서 일반적으로 아이템을 벡터 형태로 표현하고 이들 벡터 간의 유사도 계산 방법을 많이 활용
협업 필터링(Collaborative filtering)
우리가 어떤 컨텐츠를 이용하기전에 다른 사람들의 평점이나 평가를 들어본 뒤 영화를 선택하는 경우가 대부분
why?) 이거 고민하는거 자체가 시간과 돈낭비이기 때문에
이처럼 사용자가 아이템에 매긴 평점, 상품 구매 이력 등의 사용자 행동 양식을 기반으로 추천해주는 것
=> collaborative filtering
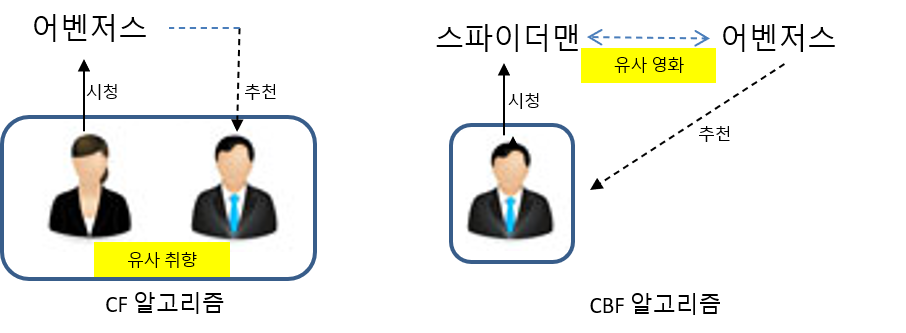
최근접 이웃 기반 협업 필터링(Nearest neighbor based collaborative filtering) == KNN
간단히 말해서 자기와 취향이 같은 친구들이 무엇을 샀는지 물어본다
데이터로부터 거리가 가까운 k개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘
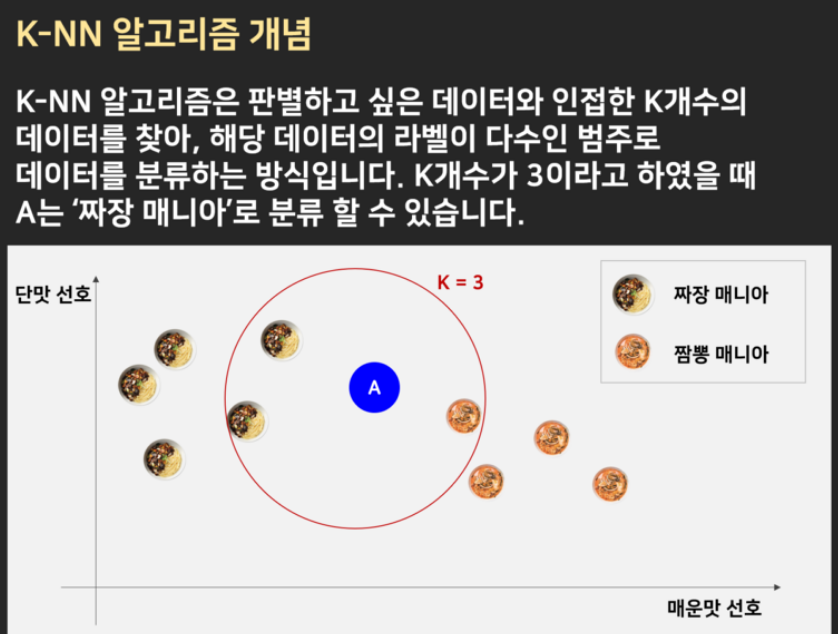
K-NN 알고리즘의 장점
- 알고리즘이 간단하여 구현하기 쉽다
- 훈련 단계가 빠르다
- 수치 기반 데이터 분류 작업에서 성능이 우수하다
K-NN 알고리즘의 단점
- 모델을 생성하지 않아 특징과 클래스간 관계를 이해하는데 제한적
- 적절한 k의 선택이 필요함
- 데이터가 많아지면 분류 단계가 필요
- 누락 데이터를 위한 추가 처리 필요
표준화
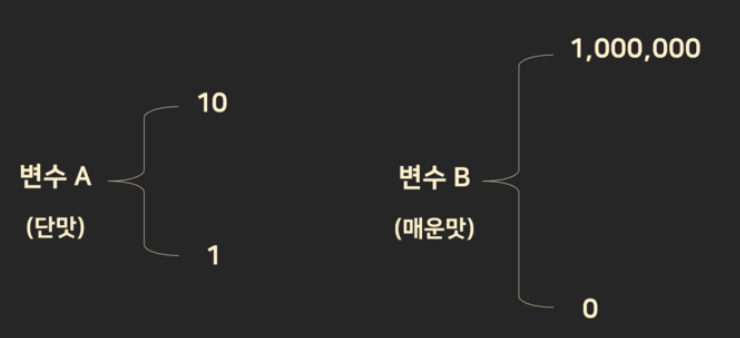
이렇게 분포가 다르게 되면 각 변수의 차이를 해석하기 어렵다. 이 때, 변수 값을 표준 범위로 재조정하기 위해 정규화 필요

'최소-최대 정규화' : 변수 X의 범위를 0% ~ 100%까지로 나타내는 방식이다. 이렇게 정규화를 할 경우 매운맛의 범위가 아무리커도 퍼센트로 나타낼 수 있어 가능하다
'z-점수 표준화': 변수 X의 범위를 평균의 위 또는 아래로 몇 표준 편차만큼 떨어져 있는지 관점으로 변수를 확대/축소하는 방식이다. z-점수는 정규화 값과 달리 미리 정의된 최소값과 최대값이 없다.
사용자 기반 협업 필터링(User based collaborative filtering)
- 비슷한 고객들이 특정 item을 소비했다
아이템 기반 협업 필터링(Item based collaborative filterting)
- 특정 item을 소비한 고객들은 다른 item도 구매했다

USER E한테 Tenet을 추천해준다
why?) Inception이랑 Tenet의 아이템 유사도가 높기 때문에 추천해주는 것
이 때 측정 수단으로 유클리디안, 코사인, 피어슨, 자카드 등의 유사도를 사용
현업에서는 아이템 기반 협업 필터링을 더 많이 사용 =>사용자 기반을 적용하기엔 개인의 취향이 너무 다양하기 때문
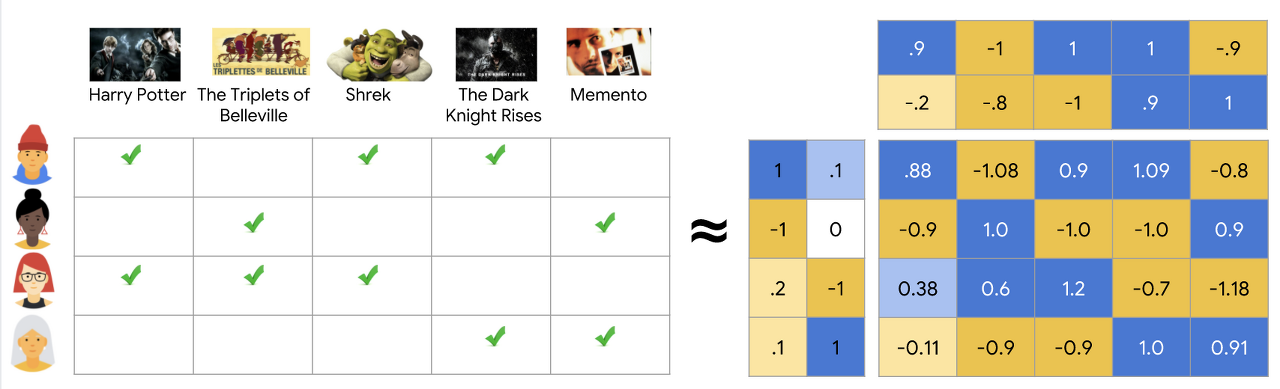
잠재 요인 협업 필터링(Latent factor based collaborative filtering)
Python pandas - pivot table(DataFrame)를 이용하여 빈칸이 존재하는 테이블을 만들고 그 빈칸들을 채워나가는 방식
근데 여기서 문제가 있다. 저렇게 하게된다면 낭비되는 메모리가 엄청 많지않나? 행렬을 N x M으로 다 만들어놓고 빈칸을 만든다니. 사진은 N,M이 작아서 그렇지 빅데이터이기 때문에 엄청나게 많은 메모리 낭비가 될수도있음
때문에 행렬 분해(Matrix Factorization) 협업 필터링을 이용하면 효과적으로 공간 절약을 할 수 있음
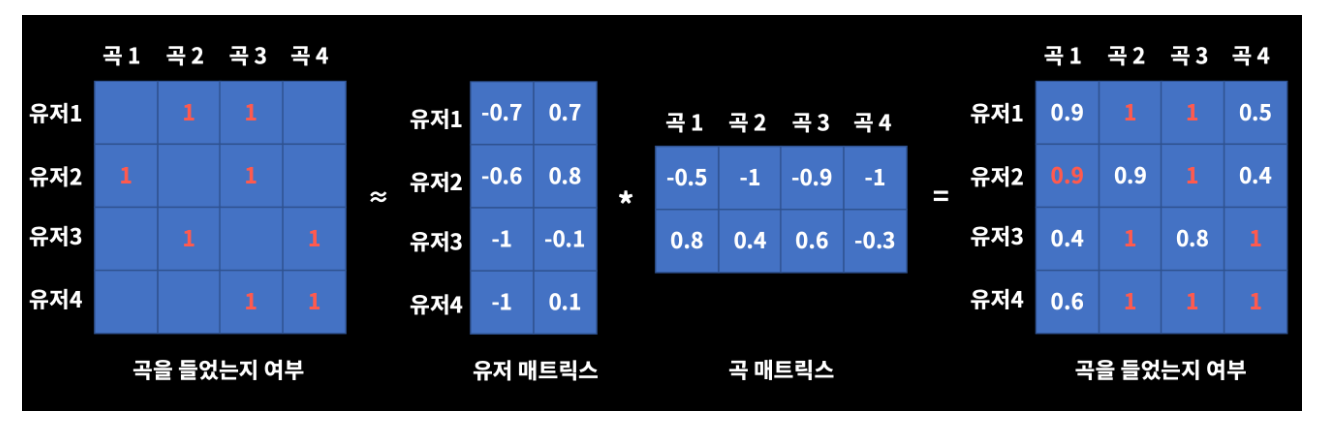
행렬 분해(Matrix Factorization) 협업 필터링
User와 Item 간의 평가 정보를 나타내는 Rating Matrix를 User Latent Matrix와 Item Latent Matrix로 분해하는 기법
하이브리드 추천 시스템(Hybrid Recommender System)
협업 필터링(Collaborative Filtering) 콘텐츠 기반 필터링(Content-based Filtering)을 조합한 새로운 알고리즘
협업 필터링은 Cold Start의 문제가 존재합니다. 이 문제를 해결하기 위해서 하이브리드 추천 시스템은 신규 콘텐츠들은 콘텐츠 기반 필터링으로 분석을 진행한 후 충분한 데이터가 쌓이게 된다면 협업 필터링으로 정확성을 높이는 방식으로 진행됩니다.
대표적인 하이브리드 추천 시스템의 예시가 바로 넷플릭스
[추천 시스템 - Surprise를 이용한 잠재 요인 협업 필터링 추천] Book-Crossing: 사용자 리뷰 평점 데이
본 포스팅은 캐글(Kaggle)에서 제공하는 'Book-Crossing 사용자 리뷰 평점 데이터 세트'를 활용하여 Surprise를 이용한 잠재 요인 협업 필터링 추천을 실습하기 위한 목적으로 작성하였습니다. Git url https
hipster4020.tistory.com
추천시스템03. 아이템 기반 협업 필터링 (collaborative filtering) 구현
협업 필터링(collaborative filtering) 사용자와 item간의 rating을 이용해서 사용자끼리 '유사도'를 찾는 방식. 특정 사용자와 유사한 사용자들이 남긴 평점, 상품구매 이력 등 행동양식 기반으로 '예측'
pearlluck.tistory.com
추천시스템04. 잠재요인 협업필터링(latent factor collaborative filtering) 구현
잠재요인 협업 필터링 (latent factor collaborative filtering) 행렬분해(Matrix Factorization)를 기반으로 사용한다. user-item 행렬 데이터를 이용해 잠재요인을 찾아낸다. 즉 user-item 행렬을 user-잠재요인, item-잠
pearlluck.tistory.com
'Backend' 카테고리의 다른 글
| [빅데이터 추천] 협업 필터링 구현해보기(아이템 기반 협업 필터링) (0) | 2023.03.09 |
|---|---|
| [빅데이터 추천] 컨텐츠 기반 필터링 구현해보기 (0) | 2023.03.09 |