






- face detection + instance Segmentation(이미지 특징 찾기)를 동시에 품
- detection만 하는 모델
Landmarks만 하는 모델이 많은데
RetinaFace는 동시에 한다
- Face classification(얼굴인지 아닌지)
Face box regression
Facial landmark regression(객체 인식)
+
Dense face regression()를 추가했더니 성능이 더 좋아졌다.
- ArcFace에 대한 설명 12:50
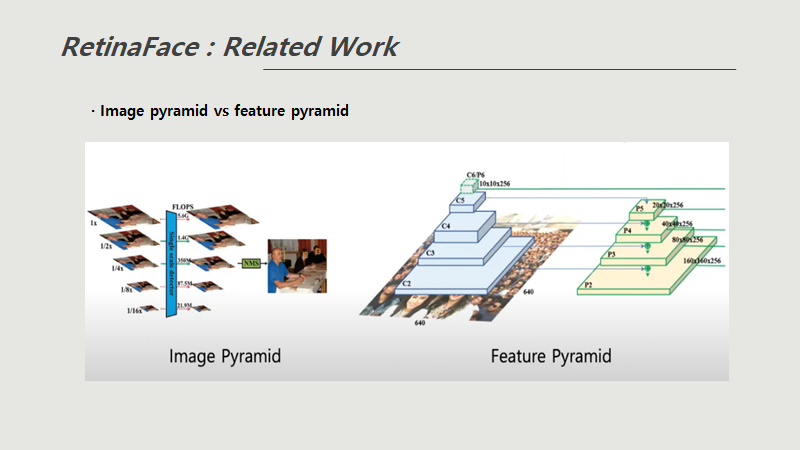
- Featurized image pyramid
이 방법은 각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지하는 방법이다.
image pyramid는 학습 시키는데 몇배의 학습이 걸림
- Two-stage는 오류가 적고 느리다
single-stage는 오류가 상대적으로 좀 있지만 빠르다(가볍다)
(RetinaNet도 single-stage)
- detection의 기술을 늘리기보다 segmention한 task를 추가했더니 성능향상
- 오토인코터 : 딥러닝을 이용한 가상의 이미지를 만드는 방법
입력 데이터의 특징을 효율적으로 담아낸 이미지를 만들어냄 이런 기술인거같음
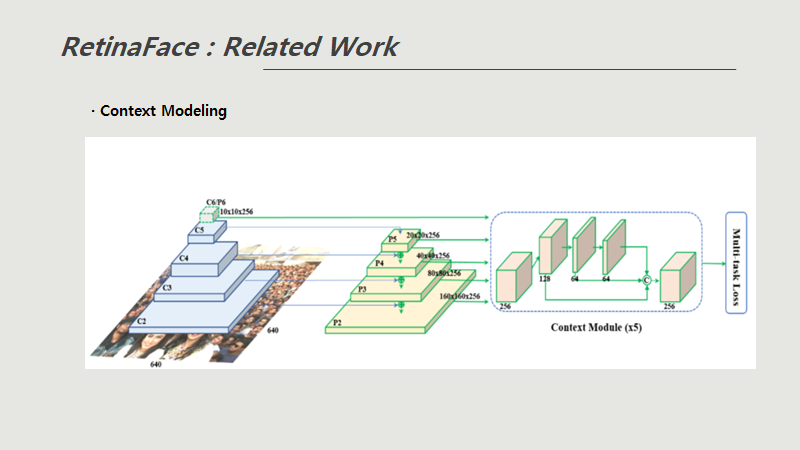
- 이미지 피라미드에서 각 scale마다 뽑고 feature 피라미드에서 특징을 뽑아낸다음
가장 작은 이미지까지 detection하기위해 context Module이라는 개념을 넣어서
컨볼루션시켜주면 작은 이미지들도 detection이 가능하다.
근데 retinaface에서 컨볼루션을 시킬 때 DCN(Deformable convolution network)를 사용
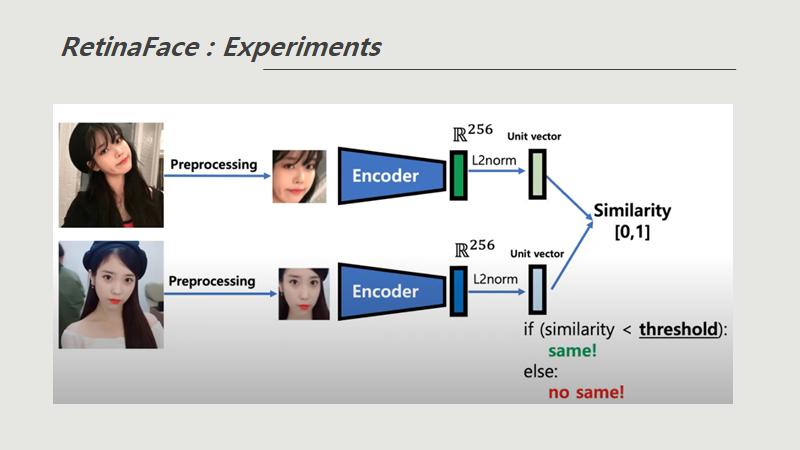
- MTCNN이랑 RetinaFace 둘다 detection하는 모델
detection하고 crop(크롭) 된게 나오면 얼마나 verification(ArcFace)를 하는지
'인공지능 > 인공지능' 카테고리의 다른 글
| EfficientDet vs Yolov5 비교 (0) | 2020.09.15 |
|---|---|
| EfficientDet의 성능 (0) | 2020.09.15 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 논문 정리 (0) | 2020.09.15 |
| CNN&MTCNN (0) | 2020.09.15 |
| 다양한 딥러닝 알고리즘 소개 (0) | 2020.09.15 |