
최단 경로 알고리즘
- 가장 짧은 경로를 찾는 알고리즘
- 각 지점은 그래프에서 노드로 표현
- 지점 간 연결된 도로는 그래프에서 간선으로 표현

다익스트라 최단 경로 알고리즘
- 특정한 노드에서 출발하여 다른 모든 노드로 가는 최단 경로를 계산
- 매 상황에서 가장 비용이 적은 노드를 선택해 임의의 과정을 반복한다
- 그리디 알고리즘으로 분류
- 현실 세계에 사용하기 매우 적합한 알고리즘
- 인공위성 GPS S/W에서 많이 사용
<동작과정>
1. 출발 노드를 설정한다.
2. 출발 노드를 기준으로 각 노드의 최소 비용을 저장한다.
3. 방문하지 않은 노드 중에서 가장 비용이 적은 노드를 선택한다.
4. 해당 노드를 거쳐서 특정한 노드로 가는 경우를 고려하여 최소 비용을 갱신한다.
5. 위 과정에서 3~4번을 반복한다.
#시간복잡도 : O(V^2), v : 노드의 개수
import heapq
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수, 간선의 개수를 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b, c))
def dijkstra(start):
q = []
# 시작 노드로 가기 위한 최단 경로는 0으로 설정하여, 큐에 삽입
heapq.heappush(q, (0, start))
distance[start] = 0
while q: # 큐가 비어있지 않다면
# 가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
dist, now = heapq.heappop(q)
# 현재 노드가 이미 처리된 적이 있는 노드라면 무시
if distance[now] < dist:
continue
# 현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = dist + i[1]
# 현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[i[0]]:
distance[i[0]] = cost
heapq.heappush(q, (cost, i[0]))
# 다익스트라 알고리즘을 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
print(distance[i])우선순위 큐(Priority Queue)
- 우선순위가 가장 높은 데이터를 가장 먼저 삭제하는 자료구조
- ex) 여러 개의 물건 데이터를 자료구조에 넣었다가 가치가 높은 물건 데이터부터 꺼내서 확인하는 경우 사용
힙(Heap)
- 우선순위 큐를 구현하기 위해 사용하는 자료구조 중 하나
- 최소 힙(Min Heap)과 최대 힙(Max Heap)이 있따.

#내림차순 힙 정렬
#최소 힙
def heapsort(iterable):
h = []
result = []
# 모든 원소를 차례대로 힙에 삽입
for value in iterable:
heapq.heappush(h, value)
# 힙에 삽입된 모든 원소를 차례대로 꺼내어 담기
for i in range(len(h)):
result.append(heapq.heappop(h))
return result#오름차순 힙 정렬
#최대 힙
def heapsort(iterable):
h = []
result = []
# 모든 원소를 차례대로 힙에 삽입
for value in iterable:
heapq.heappush(h, -value)
# 힙에 삽입된 모든 원소를 차례대로 꺼내어 담기
for i in range(len(h)):
result.append(-heapq.heappop(h))
return result개선된 다익스트라 최단 경로 알고리즘
- 방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 선택하기 위해 힙 자료 구조를 이용
- 현재 가장 가까운 노드를 저장해 놓기 위해서 힙 자료구조를 추가적으로 이용한다
- 현재의 최단 거리가 가장 짧은 노드를 선택해야 하므로 최소 힙 사용
#우선순위 큐 사용
#시간복잡도 : O(ElogV), E : 원소의 개수, V : 노드의 개수
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수, 간선의 개수를 입력받기
n, m = map(int, input().split())
# 시작 노드 번호를 입력받기
start = int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 방문한 적이 있는지 체크하는 목적의 리스트를 만들기
visited = [False] * (n + 1)
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a, b, c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b, c))
# 방문하지 않은 노드 중에서, 가장 최단 거리가 짧은 노드의 번호를 반환
def get_smallest_node():
min_value = INF
index = 0 # 가장 최단 거리가 짧은 노드(인덱스)
for i in range(1, n + 1):
if distance[i] < min_value and not visited[i]:
min_value = distance[i]
index = i
return index
def dijkstra(start):
# 시작 노드에 대해서 초기화
distance[start] = 0
visited[start] = True
for j in graph[start]:
distance[j[0]] = j[1]
# 시작 노드를 제외한 전체 n - 1개의 노드에 대해 반복
for i in range(n - 1):
# 현재 최단 거리가 가장 짧은 노드를 꺼내서, 방문 처리
now = get_smallest_node()
visited[now] = True
# 현재 노드와 연결된 다른 노드를 확인
for j in graph[now]:
cost = distance[now] + j[1]
# 현재 노드를 거쳐서 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[j[0]]:
distance[j[0]] = cost
# 다익스트라 알고리즘을 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
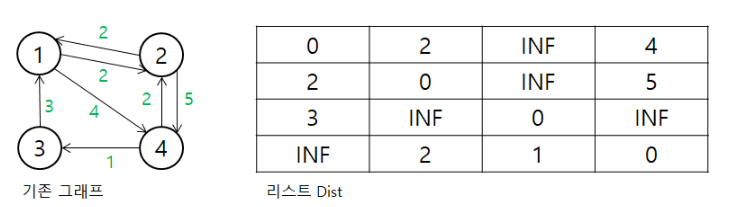
print(distance[i])플로이드 워셜 알고리즘
- 모든 노드에서 다른 모든 노드까지의 최단 경로를 모두 계산
- 거쳐 가는 노드를 기준으로 알고리즘 수행
<동작과정>
1. 하나의 정점에서 다른 정점으로 바로 갈 수 있으면 최소 비용을, 갈 수 없다면 INF로 배열에 저장
2. 3중 for문을 통해 거쳐가는 정점을 설정한 후 해당 정점을 거쳐가서 비용이 줄어드는 경우에는 값을 바꿔줌
3. 위의 과정을 반복해 모든 정점 사이의 최단 경로 탐색
import sys
INF = sys.maxsize
def Floyd_Warshall():
dist = [[INF] *n for i in range(n)]
for i in range(n):
for j in range(n):
dist[i][j] = a[i][j]
for k in range(n):
for i in range(n):
for j in range(n):
if dist[i][j] > dist[i][k] + dist[k][j]:
dist[i][j] = dist[i][k] + dist[k][j]
return dist
n = 4
a = [[0,2,INF,4], [2,0,INF,5], [3,INF,0,INF],[INF,2,1,0]]
dist = Floyd_Warshall()
for i in range(n):
for j in range(n):
print(dist[i][j], end='')
print()
'Algorithm > concept' 카테고리의 다른 글
| Coding Test(Priority Queue, Heap) (0) | 2022.04.30 |
|---|---|
| Python - 깊은 복사(Deep Copy) (0) | 2022.01.03 |
| Coding Test(다이나믹 프로그래밍) (0) | 2021.12.16 |
| Coding Test(이진 탐색) (0) | 2021.12.16 |
| Coding Test(DFS/BFS) (0) | 2021.12.15 |